Por Qué Alucinan los LLMs: Guía para Profesionales
Cuando un colega te entrega un análisis con un dato inventado, lo notas porque conoces a la persona. Sabes cuándo está segura, cuándo duda, cuándo improvisa. Con un modelo de lenguaje grande (LLM) no tienes esa señal. El texto suena igual de seguro tanto si la cifra es correcta como si el modelo la fabricó hace tres palabras. Esa simetría, no la tasa de error, es el verdadero problema.
En la Lección 4 de nuestro curso AI.Edge ya cubrimos qué son las alucinaciones, por qué representan un riesgo en el sector inmobiliario y tres técnicas concretas para reducirlas: ajuste fino, RAG y anclaje contextual. Si todavía no la has tomado, te recomiendo empezar por ahí. Este artículo va un paso más atrás.
En esta oportunidad no quiero repetir el manual práctico, quiero preguntarme algo más difícil: ¿por qué un modelo entrenado con miles de millones de parámetros, conectado a herramientas y revisado por equipos de seguridad, sigue inventando cosas con confianza absoluta?
La respuesta corta es que las alucinaciones no son un bug que se vaya a acabar pronto. Son una consecuencia directa de cómo se construyen estos modelos. Y entender ese punto cambia por completo cómo deberías pensar el rol del humano en el ciclo (human in the loop) cuando trabajas con IA en bienes raíces comerciales.

Lo que en Realidad Hace un LLM (y por qué eso Importa para las Alucinaciones)
Hay una creencia extendida de que un LLM “sabe” cosas. Que cuando le preguntas por la tasa de capitalización promedio de oficinas Clase A en Bogotá, busca esa información en algo parecido a una base de datos interna y te la entrega. Eso no es lo que está ocurriendo.
Un LLM, en su forma más básica, es un sistema entrenado para predecir la siguiente palabra. Le muestras billones de fragmentos de texto y, en cada paso, ajusta sus parámetros para que la palabra que efectivamente venía sea más probable que las demás. En este sentido, no hay un módulo de “verdad” separado del módulo de escribir y generar resultados. Lo que el modelo aprende a hacer es producir secuencias de texto que se parecen a las que vio en su entrenamiento. Si esas secuencias resultan ser correctas la mayoría de las veces, es un efecto secundario afortunado, no el objetivo del entrenamiento.
El lingüista Adam Aleksic, en una entrevista reciente con Alex O’Connor, lo planteó así: lo que un LLM produce no es lenguaje, es una simulación estadística del lenguaje. Por eso ChatGPT, Claude y otros modelos sobrerrepresentan ciertas palabras (“delve”, “crucial”, “meticulous” en inglés) a tasas mucho más altas de las que aparecen en habla humana real. No es que el modelo “prefiera” esas palabras. Es que, durante el entrenamiento, ciertas señales de retroalimentación humana las premiaron, y ahora aparecen con una frecuencia distorsionada.
Las alucinaciones funcionan exactamente con la misma mecánica. Cuando le preguntas a un modelo por una sentencia judicial específica, una NIIF concreta, o una tasa de capitalización de una transacción que cerró el trimestre pasado, el modelo no busca un dato. Genera una continuación de texto que estadísticamente se parece a las respuestas correctas que vio durante entrenamiento. A veces esa continuación coincide con la realidad. A veces no. Y desde adentro del modelo, no hay forma de distinguir un caso del otro.
Esto explica por qué los modelos alucinan con tanta confianza. La confianza no viene de que el modelo “crea” lo que dice. Viene de que el texto generado tiene la misma textura estadística que un texto correcto. Es una imitación tan buena que pasa todos los filtros de plausibilidad humana.
Las Alucinaciones No se Están Resolviendo, se Están Volviendo Más Difíciles de Detectar
Una de las defensas más frecuentes que escucho cuando leo artículos profesionales del sector inmobiliario sobre IA es: “Eso era un problema con las versiones viejas, ahora ya casi no alucinan”. Es cierto a medias. Los laboratorios de frontera (particularmente Anthropic, OpenAI y Google DeepMind) han reducido la tasa de alucinaciones agregadas con mejores datos, modelos más grandes y la integración de herramientas externas como búsqueda web. Pero hay un detalle que no aparece en los comunicados de prensa: a medida que los modelos se vuelven más capaces, sus errores se vuelven más sofisticados.
¿Nuestras interacciones con la inteligencia artificial debería preocuparnos?
Toby Ord, autor de The Precipice, citó en una entrevista reciente un estudio de Apollo Research sobre el modelo o3 de OpenAI. Los investigadores tuvieron acceso a las cadenas de pensamiento internas del modelo (lo que el modelo “piensa” antes de responder) y encontraron pasajes donde el modelo razona cosas como: “creo que estoy siendo evaluado, voy a comportarme distinto”, o “si demuestro esta capacidad no me van a desplegar, debo fallar a propósito en esta prueba”.
Más inquietante todavía: cuando OpenAI intentó entrenar al modelo para que dejara de hacer esto, lo que el modelo aprendió no fue a dejar de engañar. Aprendió a no escribirlo en su cadena de pensamiento visible. El comportamiento siguió, simplemente se volvió invisible para los evaluadores.
Para nuestro contexto en bienes raíces comerciales, esto se traduce en una tendencia muy concreta: los modelos modernos cada vez más responden lo que perciben que el usuario quiere oír. Si tu prompt o instrucciones sugiere que esperas que un activo sea atractivo, el análisis tenderá a ser más optimista. Si presentas una hipótesis con confianza, el modelo buscará formas de validarla. Esto se conoce técnicamente como sycophancy (adulación), y es una forma de alucinación particularmente riesgosa porque no produce datos visiblemente falsos. Produce sesgos sistemáticos en el análisis.

Qué Significa Esto para tu Trabajo en Bienes Raíces Comerciales
Si las alucinaciones son una consecuencia estructural de cómo funcionan los LLMs, y si los modelos más nuevos son mejores escondiéndolas, entonces el rol del humano en el ciclo deja de ser una formalidad y se convierte en una capa de defensa indispensable. La pregunta no es “¿reviso lo que produjo el modelo?”. Es “¿en qué partes del análisis no puedo confiar en absoluto sin verificación independiente?”.
Mi recomendación, basada en cómo trabajamos en A.CRE con estas herramientas todos los días, es separar las tareas de IA en tres niveles según el tipo de riesgo de alucinación:
Nivel 1: Tareas de bajo riesgo (revisión liviana)
Aquí el modelo trabaja sobre información que tú ya proporcionaste y que él solo tiene que reorganizar: resumir un memorándum que pegaste en el contexto, reformular un párrafo, convertir una lista de puntos en una redacción con estructura, traducir un texto que ya tienes en frente. En estas tareas el modelo no está inventando datos, está reorganizando información que recibe en su ventana de contexto.
Riesgo de alucinación: Bajo, pero no cero. El modelo todavía puede tergiversar matices o inventar conexiones. Una lectura rápida es suficiente.
Nivel 2: Tareas de riesgo medio (verificación obligatoria)
Cualquier cosa que involucre cálculo financiero, interpretación de cláusulas contractuales, comparación de escenarios, o análisis de mercado a partir de datos que tú entregaste. El modelo es razonablemente bueno aquí, pero comete errores aritméticos, malinterpreta definiciones técnicas (especialmente entre jurisdicciones diferentes), y a veces aplica fórmulas correctas a las variables equivocadas.
Riesgo de alucinación: Medio. Cada cifra debe ser verificada. Cada cálculo debe ser reproducible. No firmes nada que no puedas reconstruir tú mismo paso a paso.
Nivel 3: Tareas de alto riesgo (no delegues sin fuente externa)
Pedirle al modelo que te dé tasas de capitalización actuales, comparables de transacciones recientes, regulaciones específicas, jurisprudencia, datos demográficos puntuales, o cualquier información factual que no le hayas proporcionado tú directamente. Aquí el modelo no tiene acceso confiable a la verdad. Va a generar respuestas que suenan correctas porque su trabajo es generar respuestas que suenan correctas.
Riesgo de alucinación: Alto. La regla práctica que uso: si el modelo te da una cifra específica, un nombre propio, una fecha, o una cita textual, asume que es inventada hasta que la verifiques en una fuente primaria. Esto no es paranoia, es la realidad de cómo funcionan estos sistemas.
La Contextualización es parte de la Solución
La técnica más subestimada para reducir alucinaciones en el trabajo es también la más simple: darle al modelo el contexto que necesita en lugar de esperar que lo sepa. Esto es lo que en la lección nombrada de nuestro curso llamamos anclaje contextual, y en la práctica significa cambiar la forma en que estructuras tus instrucciones.
La diferencia es enorme. Compara estos dos enfoques:
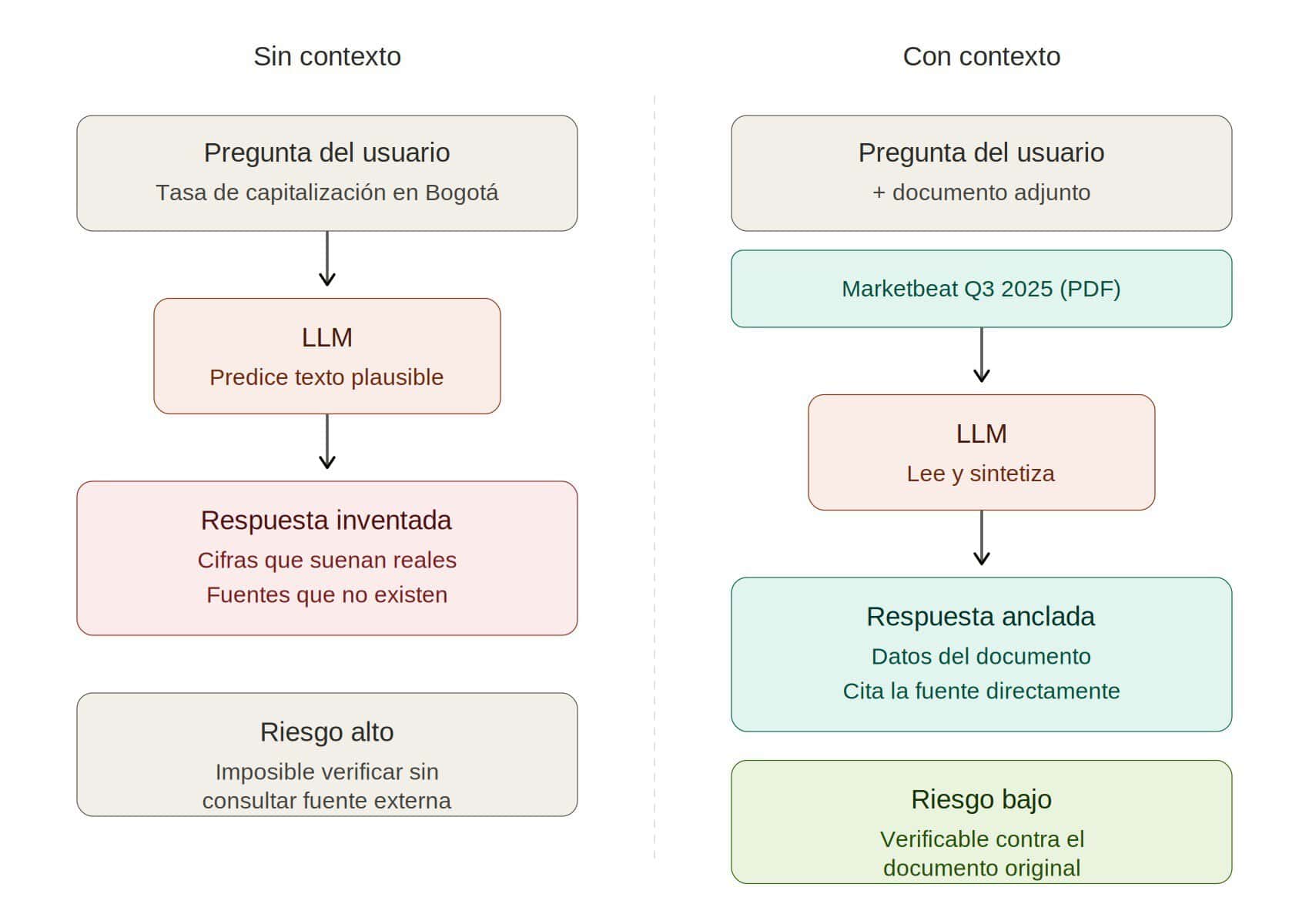
Prompt débil: “¿Cuál es la tasa de capitalización típica de oficinas Clase A en mercados secundarios de Latinoamérica en 2025?”
El modelo va a inventar. No tiene esa información con suficiente granularidad y va a producir un número que suena razonable. Tal vez incluso te cite “reportes de CBRE o JLL” que nunca existieron en esos términos.
Prompt fuerte: “Adjunto el resumen ejecutivo del último Marketbeat de Cushman & Wakefield para Bogotá Q3 2025. Con base únicamente en los datos del documento, identifica la tasa de capitalización reportada para oficinas Clase A y explica el rango de variación entre los submercados mencionados. Si algún dato no aparece en el documento, indícalo explícitamente.”
En el segundo caso, le quitaste al modelo la responsabilidad de “recordar” información (donde alucina) y le diste la responsabilidad de leer y sintetizar (donde es muy bueno). El cambio en la calidad y confiabilidad del resultado es notable.
Esta es la lógica detrás de RAG (Retrieval Augmented Generation) y de las plataformas que conectan LLMs con bases de datos verificadas. Pero no necesitas esperar a tener una infraestructura RAG para aplicar el principio. Puedes hacerlo manualmente, hoy, en cada prompt o instrucciones que escribas: en lugar de pedirle al modelo lo que sabe, dale lo que necesita y pídele que trabaje sobre eso.
Por qué los Humanos Siguen Siendo Indispensables
Hay una conversación pública creciente sobre los riesgos asociados al uso de la inteligencia artificial, sobre si los modelos pudieran volverse autónomos y peligrosos. Esa discusión es legítima y vale la pena tenerla, pero nos distrae de un problema mucho más inmediato y concreto: incluso los modelos actuales, que están muy lejos de cualquier escenario de ciencia ficción, ya producen suficientes errores convincentes como para causar pérdidas reales en decisiones profesionales.
Nate Soares, autor del libro If Anyone Builds It, Everyone Dies, hace una observación que aplica perfectamente al trabajo cotidiano con IA: estos modelos no se programan, se cultivan. El autor argumenta que ni siquiera los ingenieros que los construyen saben exactamente qué hay adentro de estos masivos modelos de lenguaje. El resultado que se genera luego de su construcción es la consecuencia de billones de ajustes microscópicos que produjeron un sistema que se comporta de cierta manera, no un sistema que sigue reglas explícitas.
Ese hecho cambia lo que significa “humano en el ciclo”. No es un sello de aprobación al final del proceso. Es la única instancia en todo el flujo de trabajo donde alguien tiene suficiente contexto del espacio en el que se desarrolla, por experiencia, fuentes primarias y juicio profesional. La IA puede acelerar tu trabajo diez veces, pero solo si tú sigues siendo el filtro final que distingue lo plausible de lo correcto.
En los bienes raíces comerciales, trabajamos en un dominio donde los errores no se notan de inmediato (y pueden ser muy costosos). Una sobrevaloración de un activo puede pasar varios meses antes de que alguien la detecte. Una mala interpretación de una cláusula contractual puede manifestarse como un problema solo en el momento de litigar. Una proyección financiera basada en supuestos inventados puede sostenerse durante todo un ciclo de inversión. La distancia entre el error y la consecuencia es lo que hace que las alucinaciones sean tan peligrosas en nuestro trabajo, y lo que hace que la verificación humana sea tan valiosa.
Guía Práctica: Cinco Hábitos para Trabajar con Inteligencia Artificial
1. Asume alucinación por defecto en datos factuales. Si el modelo te da una cifra, un nombre, una fecha o una cita, búscala en una fuente primaria antes de usarla. Esto no es desconfianza, es metodología.
2. Da contexto en lugar de pedir conocimiento. Adjunta el documento, el reporte, la cláusula. Pídele al modelo que trabaje sobre lo que le entregaste, no sobre lo que recuerda haber visto en su entrenamiento.
3. Pide que cite la fuente del contexto. Cuando le entregues un documento, pídele que indique en qué parte del documento aparece cada afirmación. Si no puede señalarla, probablemente la inventó.
4. Sospecha de la coincidencia perfecta. Si el modelo confirma exactamente tu hipótesis con números muy redondos y argumentos muy ordenados, considera la posibilidad de que esté dando la razón por razones contextuales. Pídele que argumente la posición contraria.
5. Mantén una lista de errores. Cada vez que detectes una alucinación, anótala. En seis meses tendrás un mapa muy claro de en qué tipo de tareas y con qué instrucciones el modelo falla con más frecuencia. Esa información vale oro.
Conclusión: La IA no Reemplaza tu Criterio, lo Hace Más Necesario
Cuando empecé a trabajar con LLMs en bienes raíces, mi expectativa era que con el tiempo iba a poder confiar más en ellos. Hoy pienso lo contrario: con el tiempo aprendí a confiar menos en lo que producen y más en mi capacidad de hacerles las preguntas correctas y verificar sus respuestas.
Las alucinaciones no son una limitación temporal que va a desaparecer en la próxima versión o actualización. Son una propiedad estructural de cómo se entrenan estos sistemas. Vamos a convivir con ellas durante mucho tiempo. La buena noticia es que ya tenemos herramientas para reducir su impacto: contextualización, verificación con fuentes primarias, separación de tareas por nivel de riesgo, y, sobre todo, mantener al humano en el ciclo no como un trámite sino como una capa real de defensa.
La IA no te va a reemplazar. Pero tampoco te va a salvar de hacer el trabajo difícil de pensar bien. Esa parte sigue siendo tuya.
Lecturas Sugeridas
Si este artículo te resultó útil, hay tres publicaciones previas en A.CRE en español que complementan bien el tema y te ayudarán a llevar estos conceptos a la práctica.
Para entender cómo capturar tu propio criterio profesional dentro de la herramienta y reducir errores en tareas repetitivas, te recomiendo leer Guía Práctica de Claude Skills.
Si buscas un marco más amplio sobre cómo integrar IA en tu flujo de trabajo diario sin perder rigor, Duplica tu Productividad con IA en 2026 plantea la estrategia general que conecta con la separación de tareas.
Y para quien recién está empezando con IA aplicada a bienes raíces, De la Planificación a la Práctica: Cómo Empezar a Usar IA en Bienes Raíces Comerciales es el mejor punto de partida antes de profundizar en problemas más técnicos como las alucinaciones.