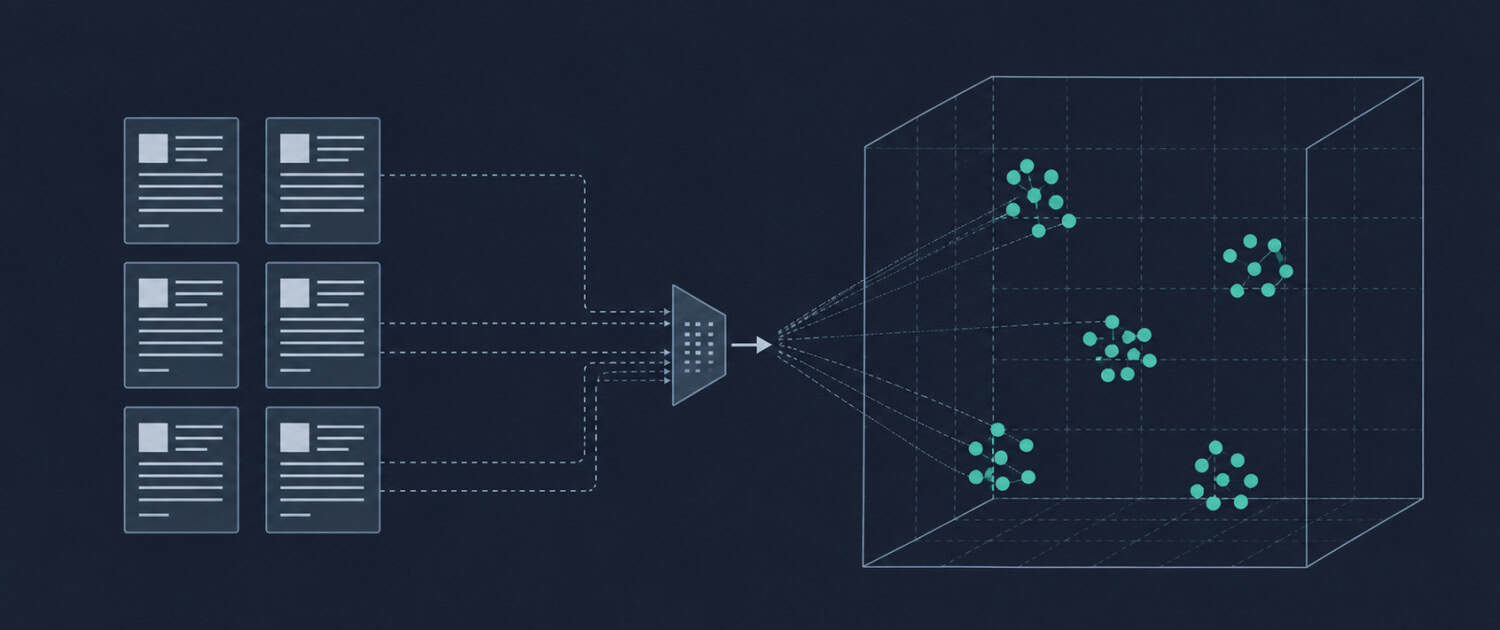
Embeddings
A mathematical representation of text, images, or other data as a vector, which is a list of numbers that captures semantic meaning. AI models use embeddings to understand and compare concepts, such that two pieces of text with similar meaning will have embeddings that are numerically close to each other. In commercial real estate, embeddings are the underlying mechanism that allows an AI system to find the most relevant lease clauses, comparable sales, or market commentary in response to a natural language query.
Putting Embeddings in Context
When a CRE analyst queries an AI system with “find lease clauses related to co-tenancy rights,” the system does not search for those exact words in a document library. Instead, it converts the query into an embedding and compares it numerically against the embeddings of every stored clause, returning the ones whose meaning is closest to the query regardless of whether they use identical phrasing. This is why a well-configured AI document system can surface a relevant clause worded as “anchor tenant vacancy provision” in response to a question that never used those words.
Frequently Asked Questions about Embeddings
Why do embeddings matter for CRE professionals building AI-powered document tools?
Embeddings are the mechanism that makes semantic search possible, which is the ability to find relevant content based on meaning rather than exact keyword matches. For CRE document workflows involving leases, appraisals, offering memoranda, and market reports, this matters because the same concept is often expressed differently across documents and authors. A keyword search for “rent abatement” will miss clauses that describe the same concept as “free rent period” or “rental concession,” while a search built on embeddings will surface all of them because their meaning is numerically similar in the vector space.
How do embeddings relate to retrieval-augmented generation in a CRE AI system?
Embeddings are the retrieval engine inside a RAG system. When a CRE professional submits a query, the system converts that query into an embedding and searches a vector database of pre-embedded documents for the closest numerical matches. Those matched passages are then passed to the language model as context before it generates a response. Without embeddings, a RAG system would have no reliable way to identify which documents or passages in a large knowledge base are actually relevant to the specific question being asked.
Does embedding quality affect the accuracy of an AI system used for CRE research?
Embedding quality directly determines how well the retrieval step performs, which in turn affects the accuracy of the final output. If the embedding model does not represent CRE-specific terminology accurately, a query about cap rate compression may fail to surface the most relevant market commentary because the numerical relationships between domain-specific terms are not well captured. General-purpose embedding models perform adequately for broad language tasks, but CRE teams building high-stakes research or underwriting tools benefit from evaluating whether their embedding model handles industry vocabulary with sufficient precision.
What is a vector database and why is it needed to work with embeddings?
A vector database is a storage system designed specifically to hold embeddings and perform fast similarity searches across them. Traditional databases store and retrieve data by exact value matching, which cannot handle the numerical proximity comparisons that embeddings require. When a CRE firm embeds its entire lease library or transaction database, those vectors need to be stored in a system that can quickly identify the closest matches to a new query vector across potentially thousands or millions of stored documents. Pinecone, Weaviate, and pgvector are examples of vector database tools commonly used in AI application development.
What are the limitations of embeddings that CRE teams should keep in mind?
Embeddings capture semantic similarity but not logical structure, numerical precision, or factual accuracy. Two statements that are semantically similar in phrasing may be retrieved together even if one contradicts the other, and a query about a specific NOI figure will not perform as well as a traditional database lookup for exact numerical data. In CRE workflows where precise financial figures, dates, or legal terms must be retrieved accurately, embeddings work best when combined with structured metadata filtering that narrows the search space before the semantic comparison occurs. Relying on embeddings alone for exact-match retrieval tasks introduces retrieval errors that can be difficult to detect without systematic output auditing.
Click here to get this CRE Glossary in an eBook (PDF) format.