Retrieval-Augmented Generation (RAG)
A technique that improves an AI model’s responses by retrieving relevant information from an external knowledge base at the time of a query, rather than relying solely on the model’s training data. In commercial real estate, RAG allows an AI tool to pull current market data, a specific lease clause, or an underwriting methodology from a curated knowledge base before generating a response, significantly reducing inaccuracies and keeping outputs grounded in real, up-to-date information. The A.CRE Intelligence Hub is an example of a RAG-powered system built specifically for CRE professionals.
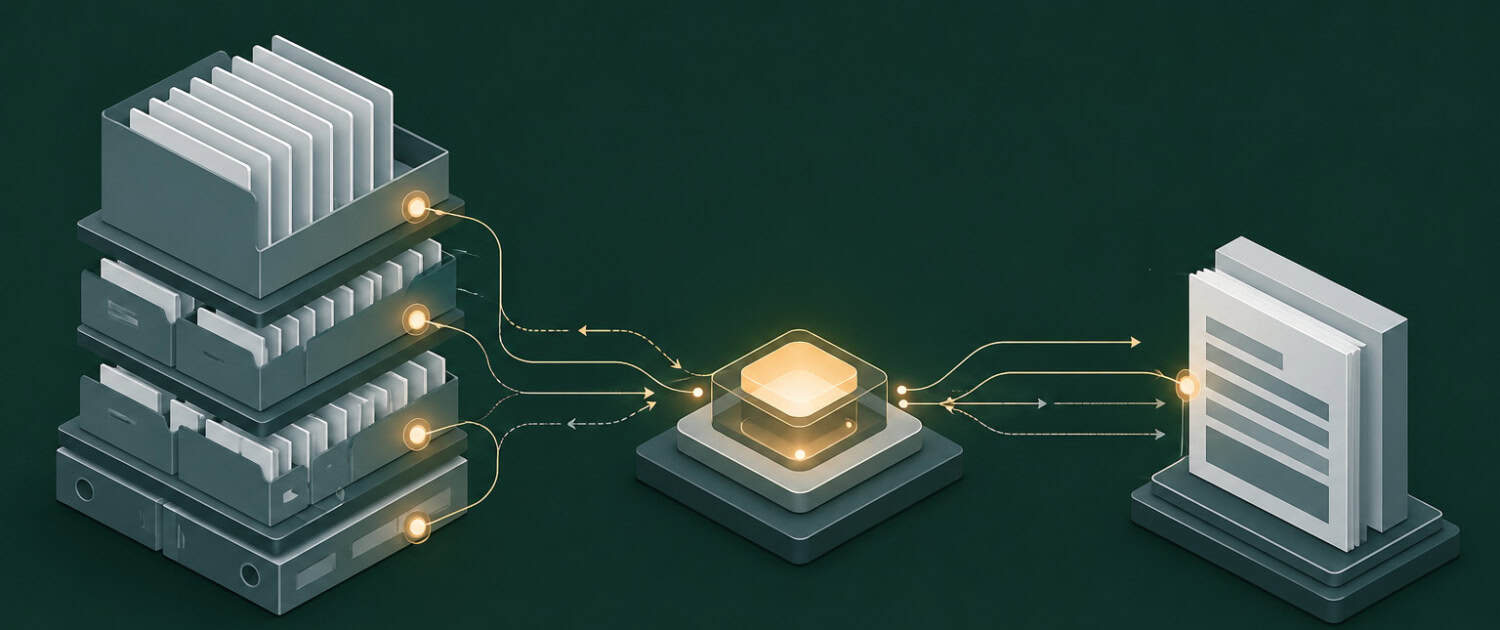
Putting Retrieval-Augmented Generation (RAG) in Context
An acquisitions analyst asks an AI tool what the current cap rate range is for Class A industrial assets in the Inland Empire. Without RAG, the model answers from training data that may be months or years out of date. With RAG, the system first queries a connected market database, retrieves the most recent broker survey or transaction comps, and incorporates that data directly into its response, producing an answer the analyst can act on rather than one that requires manual verification.
Frequently Asked Questions about Retrieval-Augmented Generation (RAG)
How does RAG differ from a standard AI model in a CRE context?
A standard AI model generates responses entirely from patterns learned during training, which means its knowledge has a fixed cutoff date and no access to proprietary or firm-specific data. A RAG-enabled system adds a retrieval step that queries a connected knowledge base before generating a response, allowing it to incorporate current market data, internal deal files, or curated underwriting guidelines. For CRE professionals, this distinction matters because the accuracy of outputs on deal-specific questions depends directly on whether the model has access to current, relevant source material.
What types of knowledge bases are most useful to connect to a RAG system for CRE workflows?
The most useful knowledge bases for CRE RAG applications are those containing information the model cannot reliably generate on its own: current market reports, lease abstracts, rent rolls, underwriting templates, cap rate surveys, and proprietary deal memos. Internal document libraries, structured databases of comparable transactions, and curated methodology guides are also strong candidates. The quality of the retrieval step depends heavily on how well the knowledge base is organized and indexed, so document structure and metadata matter as much as content.
How does RAG reduce the hallucination risk that concerns many CRE professionals?
Hallucination occurs when a model generates plausible-sounding but factually incorrect information, which is a significant risk when an AI tool is asked about specific lease terms, market statistics, or transaction details it was never trained on. RAG mitigates this by grounding the model’s response in retrieved source documents rather than inference alone. When the system retrieves and cites the actual lease clause or market report before generating its answer, the output is traceable and verifiable, which is the standard CRE professionals need before using AI-generated content in a deal process.
What are the limitations of RAG that CRE teams should understand before implementing it?
RAG is only as reliable as the knowledge base it retrieves from. If the connected documents are outdated, poorly structured, or incomplete, the retrieval step will surface low-quality source material and the model’s response will reflect that. RAG also introduces latency, as the retrieval step adds processing time before a response is generated. Teams should also recognize that retrieval is not perfect: a relevant document may exist in the knowledge base but fail to surface if the query is phrased in a way that does not match the document’s indexing. Ongoing curation of the knowledge base is a maintenance cost that is easy to underestimate.
Can a CRE firm build its own RAG system without a large technical team?
Purpose-built RAG platforms and no-code tools have made it increasingly feasible for smaller CRE firms to implement retrieval-augmented workflows without a dedicated engineering team. Tools that connect document libraries to AI interfaces through API integrations or pre-built connectors allow firms to configure a basic RAG system around their existing document repositories. However, the knowledge base design, document preparation, and ongoing maintenance still require deliberate operational investment. Firms that treat RAG as a plug-and-play solution without addressing data quality and curation typically see limited gains over a standard AI model.
Click here to get this CRE Glossary in an eBook (PDF) format.